
the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 26 May 2021
| 26 May 2021
Herd clustering strategies and corresponding genetic evaluations based on social–ecological characteristics for a local endangered cattle breed
Jonas Herold
Kerstin Brügemann
Sven König
The accuracy of breeding values strongly depends on the population and herd structure, i.e., the number of animals considered in genetic evaluations and the size of contemporary groups (CGs). Local breeds are usually kept in small-sized family farms under alternative husbandry conditions. For such herd structure, consideration of classical herd or herd-test-day effects in CG modeling approaches implies only a few records per effect level. In consequence, the present study aimed on methodological evaluations of different herd clustering strategies, considering social–ecological and herd characteristics. In this regard, we considered 19 herds keeping cows from the small local population of German Black Pied cattle (Deutsches Schwarzbuntes Niederungsrind; DSN), 10 herds keeping Holstein Friesian (HF) cows and one mixed herd with HF and DSN cows. Herds were characterized for 106 variables, reflecting farm conditions, husbandry practices, feeding regime, herd management, herd fertility status, herd health status and breeding strategies as well as social–ecological descriptors. The variables were input data for different clustering approaches including agglomerative hierarchical clustering (AHC), partition around medoids (PAM), fuzzy clustering (FZC) and a clustering of variables combined with agglomerative hierarchical clustering (CoVAHC). The evaluation criterion was the average silhouette width (ASW), suggesting a CoVAHC application and consideration of four herd clusters (HCs) for herd allocation (ASW of 0.510). HC1 comprised the larger, half organic and half conventional DSN family farms, which generate their main income from milk production. HC2 consisted of small organic DSN family farms where cows are kept in tie stables. HC3 included the DSN sub-population from former East Germany, reflecting the large-scale farm types. The specialized HF herds were well separated and allocated to HC4. Generalized linear mixed models with appropriate link functions were applied to compare test-day and female fertility traits of 5538 cows (2341 DSN and 3197 HF) from the first three lactations among the four HCs. Least squares means for milk, fat and protein yield (Mkg, Fkg and Pkg) significantly differed between HC. The significant differences among the four HCs clearly indicate the influence of varying herd conditions on cow traits. The similarities of herds within HC suggested the application of HCs in statistical models for genetic evaluations for DSN. In this regard, we found an increase of accuracies of estimated breeding values of cows and sires and of heritabilities for milk yield when applying models with herd-cluster-test-day or herd-cluster-test-month effects compared to classical herd-test-day models. The identified increase for the number of cows and cow records in CG due to HC effects may be the major explanation for the identified superiority.
- Article
(696 KB) - Full-text XML
-
Supplement
(307 KB) - BibTeX
- EndNote





Local cattle breeds contribute to genetic diversity and may carry favorable alleles with relevance for future production systems and market requirements, justifying efforts for the implementation of preservation programs (Ajmone-Marsan et al., 2010; Toro et al., 2011). Numerous studies (Toro et al., 2011; Fernández et al., 2011; Biscarini et al., 2015; Mastrangelo et al., 2016; Cervantes et al., 2016) focused on strategies to maintain genetic variability in endangered breeds and especially focused on the minimization of inbreeding and genetic drift. A major feature of local endangered cattle breeds is their ability for adaptation to harsh environments (Fernández et al., 2011; Cervantes et al., 2016). In consequence, local cattle breeds are mostly kept in alternative production systems, reflecting a broad pattern of challenges such as limited food resources or climatic stress (Halli et al., 2020). In Germany, the local dual-purpose cattle breed German Black Pied cattle (Deutsches Schwarzbuntes Niederungsrind; DSN) is used for dairy cattle farming mainly in small-sized organic herds reflecting harsh environments. The DSN breeding goal considers both milk and meat production, and it focuses on genetic improvements for longevity and female fertility. The current DSN population size comprises about 3500 registered cows (Jaeger et al., 2018).
Accurate genetic evaluations in DSN are imperative, because several German breeding organizations sell semen from DSN sires worldwide. DSN and Holstein Friesian (HF) cattle are considered simultaneously in genetic evaluations, but their genetic connectedness is quite low, implying biased estimated breeding values (EBVs) when ignoring further genetic model improvements. In such context, Jaeger et al. (2019) suggested improved genetic evaluations for DSN through a widened population size, i.e., considering DSN cows from the Netherlands and from Poland.
In addition to the small DSN population size, accuracy of selection and genetic evaluations is hampered due to the small-sized herd structures. Classically, genetic evaluation models consider a herd effect, because the herd usually represents same management, feeding or husbandry conditions for all cows from the same herd. However, genetic (co)variance components and EBVs might be biased when creating specific management groups within herds or when applying preferential treatment for specific cow groups (König et al., 2005). Accordingly, Kennedy and Trus (1993) stretched the topic of contemporary groups (CGs) in genetic evaluations, which should represent the microenvironment as detailed as possible. The influence of the herd effect when modeling CGs is not constant throughout the year, implying consideration of a further time-dependent explanatory variable, i.e., via herd-year-season or herd-test-day modeling (Emmerling, 2000). However, such modeling approaches might be problematic in the case of small herd sizes, implying only a few cow records per CG, with detrimental impact on selection accuracy (Strabel et al., 2005; Pereira et al., 2018). Furthermore, human–animal relationships reflecting social characteristics determine herd effects. Social characteristics plus classical environmental conditions (e.g., climate, feeding resources) were considered when defining social–ecological systems for livestock classifications (Martin-Collado et al., 2014). In small-sized DSN family farms, Ebinghaus (2018) identified impact of the individual farm management and human–animal interactions on variations of disease incidences and production levels across herds (Ebinghaus, 2018).
Alternative modeling strategies to create CG were introduced by Strabel et al. (2005) and Vasconcelos et al. (2008). They grouped herds according to herd size or average milk yield per herd. Grouping herds according to herd, environmental or social characteristics points to the application of herd clustering strategies. Table 1 gives an overview of the clustering methods as applied in cattle populations. Key factors to allocate herds to herd clusters (HCs) were the overall production system (conventional or organic), herd size, breed, country or region (Blanco-Penedo et al., 2019; Ivemeyer et al., 2017). Tremblay et al. (2016) recommended that clustering approaches should consider variables reflecting herd particularities.
Table 1Overview for applied herd clustering approaches.
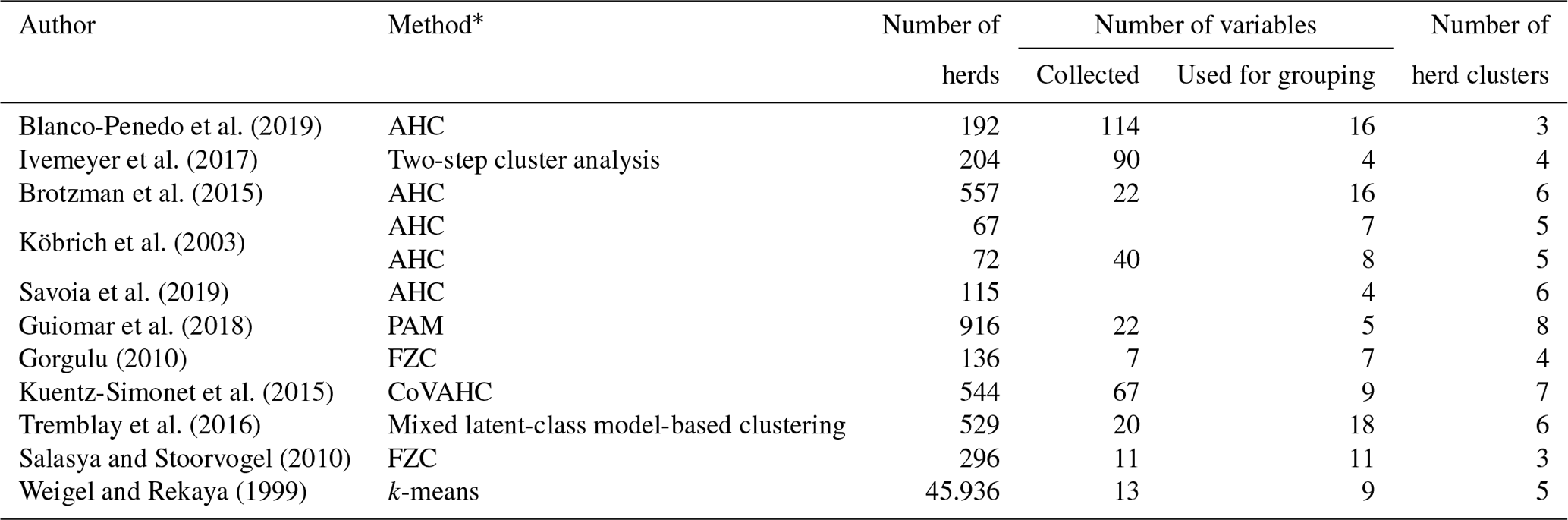
* AHC is agglomerative hierarchical clustering, PAM is the partition around medoids, FZC is fuzzy clustering, CoVAHC is the clustering of variables combined with agglomerative hierarchical clustering, and k-means clustering is the nearest centroid method.
The objective of this study was to evaluate different HC strategies including a sample of DSN herds and some HF herds, with the aim of defining appropriate CGs in genetic evaluations. Created clusters will be described based on descriptive statistics for HC variables, as well as on detailed analyses for cow traits in respective HCs using mixed model applications. In a last step, we evaluated the impact of HC modeling on genetic parameter estimates and on accuracies of genetic evaluations.
2.1 Herd characterization
Herd data were collected via face-to-face interviews and farm characterizations between September 2017 and March 2018, considering 19 DSN herds, 10 HF herds and one mixed herd keeping both breeds. The 19 DSN herds reflected “pure” DSN herds with DSN gene percentages larger than 87.5 %, considering the algorithm for gene percentage calculations as developed by Jaeger et al. (2018). Also the DSN cows in the mixed herd were pure DSN. The HF herds were chosen to consider a genetically related breed, but with opposite breeding goals, production levels and farming systems. The participating herds were located in three major geographic regions from Germany: (1) intensive grazing systems on coastal marshlands, (2) large-scale farms (indoor system) in one region of former East Germany and (3) small-scale family farms in the middle of Germany (semi-intensive grazing systems with maximal 5 h grazing per day). The altitudes of farms in the three regions were 14.68, 84.00 and 200.47 m, respectively, and the latitudes were 53∘28′, 51∘67′ and 51∘12′, respectively. The median herd size for all herds comprised 95 milking cows, ranging from 3 to 800 cows (median 35.5) for DSN and from 60 to 780 cows (median 156.5) for HF.
The farm visits for structured interviews and herd characterizations comprised 45 to 90 min per farm. The survey and visual herd observations included quantitative and qualitative information with regard to general herd characteristics, the feeding regime, the housing system, the husbandry practices, the herd and pasture management, herd fertility and health status as well as the management of calves, heifers and dry cows. Social components addressed, e.g., the herd manager's education, the expenditure of time used for dairy cattle farming, the family status, the number and age of the children and the number of farm employees. In total, the herd characterization comprised 117 variables (26 quantitative and 91 qualitative variables) as indicated in the Supplement (Table S1). Answers were possible via multiple choice but also included open questions and required specific numeric values in some cases (Supplement Table S1). Quantitative variables were scaled by a z transformation, implying a mean of 0 and a variance of 1 (Gagaoua et al., 2018). The data collection was carried out by the same interviewer, so that a misinterpretation of questions by the farmer can be excluded.
2.2 Herd clustering approaches
The previously applied HC approaches (as summarized in Table 1) focused on one specific method. In the present study, we compared four different HC methods, especially from the perspective of HC consideration in genetic evaluations. The following four different HC methods were applied: (i) agglomerative hierarchical clustering (AHC), (ii) partition around medoids (PAM), (iii) fuzzy clustering (FZC) and (iv) a clustering of variables combined with agglomerative hierarchical clustering (CoVAHC). All clustering analyses were conducted in R version 4.0.2 (R Core Team, 2020) and applying the packages “cluster” (Maechler et al., 2018) and “ClustOfVar” (Chavent et al., 2017). According to Pimenta et al. (2017), herd variables indicating limited variation or strong correlations with other variables, were deleted. After herd variable editing, 106 variables (23 quantitative and 83 qualitative variables) remained for the ongoing cluster analyses. Based on the mixed data types (nominal, ordinal, (a)symmetric binary, metric), the Gower distance (Gower, 1971) modified by Struyf et al. (1996), was used to calculate the dissimilarity matrix. The overall average silhouette width (ASW) as defined by Rousseeuw (1987) was used to evaluate the clustering approaches and to identify the optimal number of HCs. The silhouette width ranges between −1 and 1, whereby a good cluster separation is characterized by a high intra-homogeneity and inter-heterogeneity with values close to 1 (Rousseeuw, 1987; Lletí et al., 2004; Gagaoua et al., 2018). For all clustering approaches, we calculated the ASW for each number of HCs (evaluated range: 2–10; according to the studies as listed in Table 1).
Agglomerative hierarchical clustering (AHC): The aim of this algorithm is to identify a hierarchical clustering of elements based on similarities or dissimilarities. Initially, each element is considered as a single cluster. Afterwards, these clusters are merged stepwise until the complete data set becomes a cluster (Struyf et al., 1996; Köbrich et al., 2003). The approach recommended by Ward (1963) was used to create homogeneous clusters by fusion. This approach is based on a classical sum-square criterion and produces clusters that minimize variation within the group at each merging step (Murtagh and Legendre, 2014). The dissimilarities can be used to visualize each merging steps in a dendrogram with horizontal lines indicating a combination of herds or HCs.
Partition around medoids (PAM): This method is an upgrade of the popular k-means algorithm, which is fast, efficient and simple. k-means clustering only handles numeric values, but PAM also works with ordinarily scaled variables (Maione et al., 2019). PAM is more robust to outliers than k-means clustering, because it minimizes the sum of non-squared dissimilarities instead of the sum of squared Euclidean distances (Kaufman and Rousseeuw, 1990; Struyf et al., 1996). PAM searches for k medoids (the representative elements) within the data set (Kaufman and Rousseeuw, 1990) and minimizes the total dissimilarity of each element to its nearest medoid.
Fuzzy clustering (FZC): In contrast to AHC and PAM, where each element belongs exactly to one cluster, FZC is a so-called soft clustering algorithm. This means that an element can be assigned to varying clusters. Each element receives a membership value that indicates how strongly the element belongs to any cluster (Struyf et al., 1996; Salasya and Stoorvogel, 2010). The membership exponent r[1→∞] describes the degree of fuzziness, where r=1 is comparable to a strict clustering such as AHC or PAM, and r=∞ is the highest degree of fuzziness (Salasya and Stoorvogel, 2010).
We varied r in the range from 1.0 to 4.0. The best HC differentiation was realized for r=1.1. Hence, all of the following presented results are based on r=1.1.
Clustering of variables combined with agglomerative hierarchical clustering (CoVAHC): CoVAHC is a combination of “clustering of variables” (herd information) followed by an AHC (see above) of the resulting “synthetic variables”. The aim of the “clustering of variables” (CoV) is to find a partition (one that contains similar information) in a mixed data set, in which variables are arranged in homogeneous groups by means of a hierarchical algorithm. This algorithm forms a set of p partitions of variables according to the following scheme:
-
Start partition: each variable is one start cluster.
-
Two clusters will be merged to a new partition when the dissimilarity is the smallest, so that the loss of homogeneity of the new cluster is minimal. This merging step is repeated until each variable is grouped with another variable or partition.
-
End partition: all start clusters form one complete cluster.
The CoV focuses on two aspects. The first is merging closely related variables by grouping them into partitions that maximize the homogeneity criterion, which is defined by the sum of squared Pearson correlations for quantitative variables and correlation ratios for qualitative variables. If all quantitative variables and all qualitative variables in a cluster are correlated (or anti-correlated) or the correlation ratios are equal to 1, the homogeneity criterion is maximized. The second aspect focuses on the definition of a synthetic variable of each cluster by a principal component approach for mixed data. Afterwards, the values of the synthetic variables are used via AHC to cluster the herds (Chavent et al., 2012; Brida et al., 2014).
2.3 Comparison of herd clusters for cow traits
In this regard, due to the largest ASW, we considered the four HCs to be created by the CoVAHC application (details are presented in Sect. 3.1). Cow traits were from the recording years 2017 and 2018. The number of cows per HC was as follows: HC1 of 1091 cows, HC2 of 64 cows, HC3 of 1059 cows and HC4 of 3324 cows. Production data considered 55 181 repeated test-day records from 5538 cows (19 964 records from 1947 DSN cows and 35 217 records from 3591 HF cows) for milk yield (Mkg), protein yield (Pkg), fat yield (Fkg) protein percentage (P%), fat percentage (F%), somatic cell sore (SCS) and fat-to-protein (FPR) ratio from the first to the third lactations. Female fertility traits included the interval from calving to first insemination (CFI) and the success of a first insemination (SFI). In this regard, we considered 6100 observations for CFI from 4562 cows (2548 records form 1871 DSN cows, and 3552 records from 2691 HF cows) and 7333 first inseminations for SFI from 5119 cows (3119 records form 2096 DSN cows, and 4214 records from 3023 HF cows). The udder health indicator somatic cell count (SCC) was log transformed into SCS = log2 (SCC 100 000 cells) + 3 (Ali and Shook, 1980).
Linear mixed models were applied to assess the effect of defined HC on the cow test-day traits: Mkg, Pkg, Fkg, P%, F%, SCS and FPR. All calculations were performed with R version 4.0.2 (R Core Team, 2020) and applied the package “emmeans” (Lenth, 2020). This package was also used to calculate least squares means (LSMs) for traits within HCs and to test for corresponding significant differences. The respective model (model 1) was defined as follows:
where μ is the overall mean effect, and the fixed effects are as follows: B is the breed (DSN or HF), YS is the year season of calving (December–February, March–May, June–August or September–November), L is the lactation number (1, 2 or 3), HC is the herd cluster (HC1, HC2, HC3 or HC4), DIM is the fixed regression on days in milk (Legendre polynomials of third order), and CA is the calving age as covariate (linear regression), A is the animal as a random effect, and e is the random residual effect.
A linear mixed model was applied to CFI, and a generalized linear mixed model with a logit-link function was applied to SFI. Effects in the respective model (model 2) were the same for both female fertility traits and defined as follows:
where μ is the overall mean effect, and the fixed effects are as follows: B is the breed (DSN or HF), MI is the month of insemination (January–December), L is the lactation number, HC is the herd cluster, SE is the type of semen (fresh semen, deep frozen semen, natural mating), and CA is the age at insemination as covariate (linear regression); as random effects, A is the animal and S is the service sire, and e is the random residual effect.
2.4 Genetic evaluation models
Genetic evaluations for test-day milk yield considered phenotypic data from calving years 2012 to 2018 from the 5538 cows with 55 181 test-day records (35 217 records from DSN and 19 964 records from HF) from the first three lactations. The estimation of genetic parameters and breeding values was carried out for a test-day model (model 3) with a herd-test-day (HTD) or herd-cluster-test-day (HCTD) effect and for an alternative test-month model (model 4) with a herd-test-month (HTM) or herd-cluster-test-month (HCTM) effect. Again, we considered the four HCs from the CoVAHC approach. For the genetic parameter estimations with the DMU software package (Madsen and Jensen, 2013), the following linear animal models were defined:
where yijklmnop is the test-day milk yield, μ is the overall mean; Bi is the fixed breed effect; YSj is the fixed year season of calving effect (1–27); LAk is the fixed lactation effect (1, 2, 3); HTDl or HCTDl is the fixed effect of herd test day or herd-cluster test day; HTMl or HCTMl is the fixed effect of herd test month or herd-cluster test month; DIMm is the fixed regression on days in milk using Legendre polynomials of third order; CAn is the calving age as covariate (linear regression); Ano is the random additive genetic effect; PEp is the random permanent environmental effect; eijklmnop is the random residual effect.
3.1 Evaluation of herd clustering approaches
The first step was to determine the optimal number of HCs. Figure 1 shows the ASW for the four clustering methods, indicating a wide range from 0.015 (FZC with 10 HC) to 0.510 (CoVAHC with four HCs). Such huge variation for ASW displays the differences in separation efficiency of the different approaches. The ASW was highest (0.510) when creating four HCs and applying CoVAHC clustering. Such desired value for ASW for selected clustering procedures is in agreement with Gorgulu (2010), Ivemeyer et al. (2017) and Guiomar et al. (2018). For the remaining clustering approaches AHC, PAM and FZC, the ASW was quite stable in dependency of HC variations, but generally, ASW obviously declined for more than four HCs (Fig. 1).
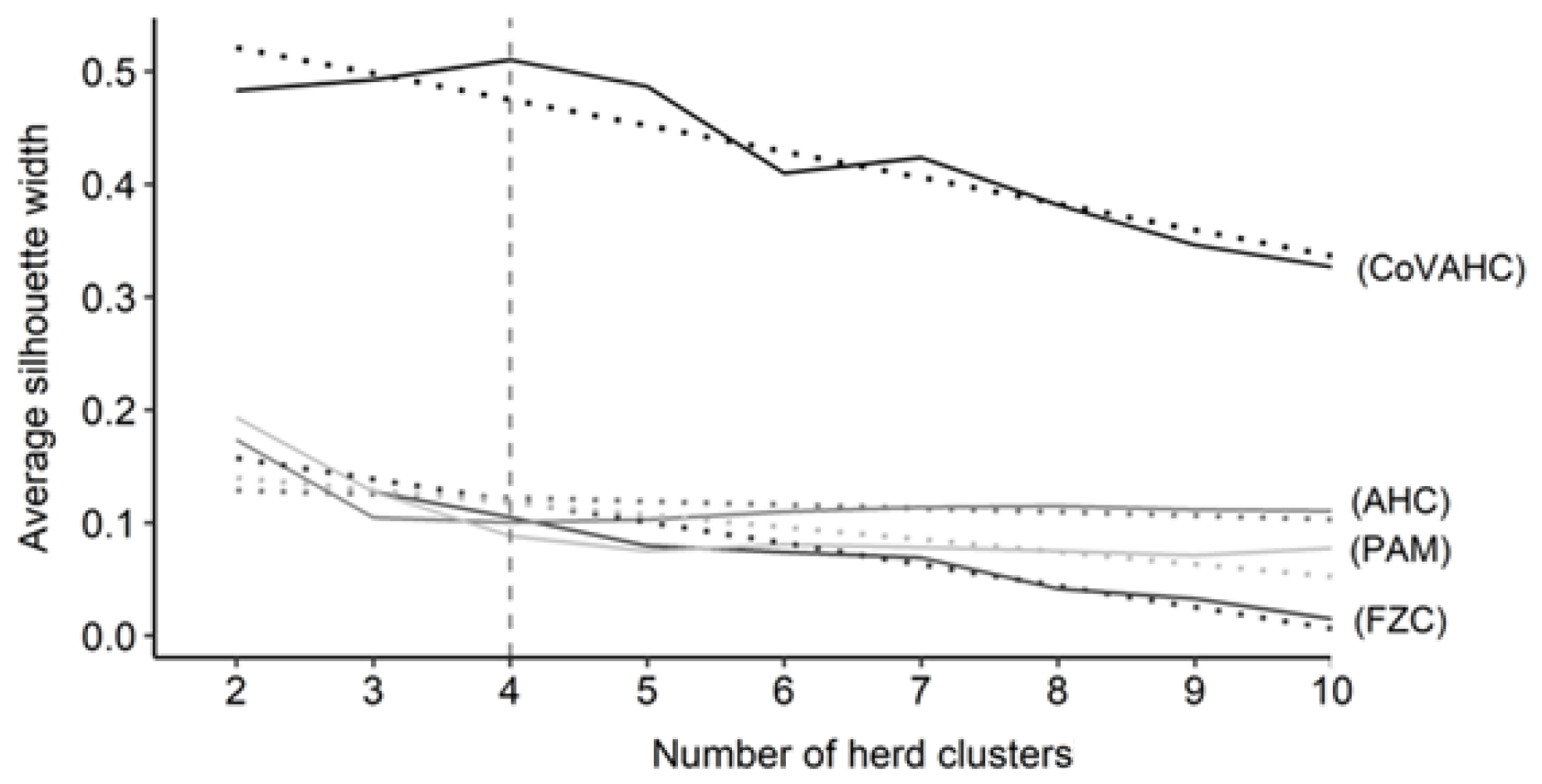
Figure 1Average silhouette width for the different numbers of herd clusters considering the following clustering approaches: agglomerative hierarchical clustering (AHC), partition around medoids (PAM), fuzzy clustering (FZC), clustering of variables combined with agglomerative hierarchical clustering (CoVAHC); dotted lines are smoothed conditional means; the vertical dotted line indicates the chosen number of herd clusters for ongoing studies.
In the Supplement (Fig. S1), ASWs for individual herds are shown. The different herd numbers as presented on the y axis are consistent for all clustering approaches and followed the herd numbering from the CoVAHC approach. The same design and pattern of bars represent the best overlap of herds in relation to the HCs as created by CoVAHC. Nevertheless, differences in herd separation accuracy among the clustering methods are very obvious. The CoVAHC application implied the largest silhouette width for all herds apart from herd 2, due to the missing contemporary herds in HC3. Individual herds displaying a negative silhouette do not reflect the characteristics of the remaining herds from the same HC, indicating misclassifications. Such misclassifications are very obvious for AHC, with negative silhouettes for the entire HC3 and herd 25. PAM displayed fewer misclassifications (only for herds 1, 11 and 12). With regard to FZC, only herd 12 indicated an incorrect HC assignment. Nevertheless, the ASW from the FZC approach indicated herd allocation inferiority compared to CoVAHC.
The evaluations of HCs in the present study focused on aspects with relevance for data recording and for genetic evaluations. The collected herd characteristics in this study represented different types of data, i.e., qualitative or quantitative. In order to overcome such obstacles, previous studies (Toro-Mujica et al., 2012; Riveiro et al., 2013; Ivemeyer et al., 2017; Blanco-Penedo et al., 2019) applied principal component analysis (PCA) to translate the categorical data structure indirectly into quantitative variables. These studies suggested a PCA due to the pronounced variation as identified among the most important principal components. To prevent possible biases through indirect transformations, Struyf et al. (1996) suggested a modified Gower distance. As a further method for handling mixed data types, Chavent et al. (2012) applied CoVAHC. They favored this approach over PCA, because more information can be taken into account when clustering the elements (herds). Furthermore, in contrast to PCA, orthogonality of the principal components is not required (Kuentz-Simonet et al., 2017).
3.2 Description of herd clusters for the optimal clustering approach (CoVAHC)
The four HCs formed by CoVAHC, which are shown in Fig. 2, differ in multiple farm characteristics (Table 2), which in turn were used to describe the HC. The two breeds (DSN and HF) were clearly separated, meaning that HF herds only appeared in HC4. Overall, 91 % of herds from HC4 represented HF, and only 9 % were DSN herds. The percentage of DSN herds in HC1, HC2 and HC3 was 100 %. Such herd allocation based on herd characteristics indicates that the evolutionarily closely related DSN and HF breeds (Biedermann et al., 2005) are kept in different production systems representing a different herd management. The DSN are mostly kept in low input or grassland systems (Jaeger et al., 2018), but HF mostly in free-stall farms applying all available modern management instruments especially with regard to feeding strategies (e.g., feeding of total mixed rations) (König et al., 2005). Accordingly, Ivemeyer et al. (2017) clearly separated HF from local breeds with small population size such as original Angler cattle or DSN. Tremblay et al. (2016) only considered herds in automatic milking systems. Despite the same milking technology, they identified obvious differences in production pattern, feeding and management characteristics between small (Jersey, Guernsey, Ayrshire) and large populations (HF, brown Swiss).
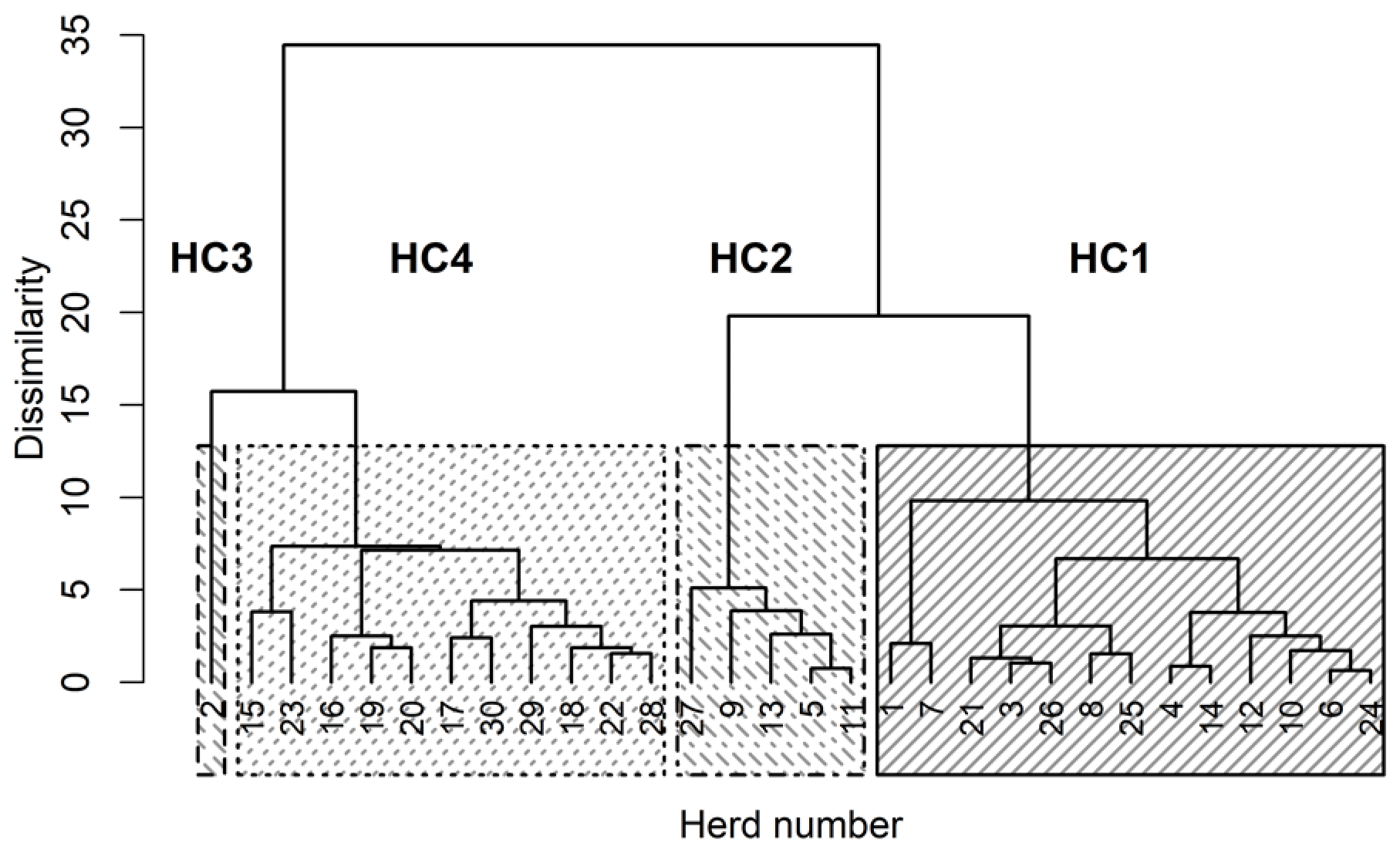
Figure 2Dendrogram of the herds merged to herd clusters by clustering of variables combined with agglomerative hierarchical clustering (CoVAHC). Each block with specific pattern represents one HC.
Table 2Percentages and values of main herd characteristics displaying significant1 herd cluster differences.
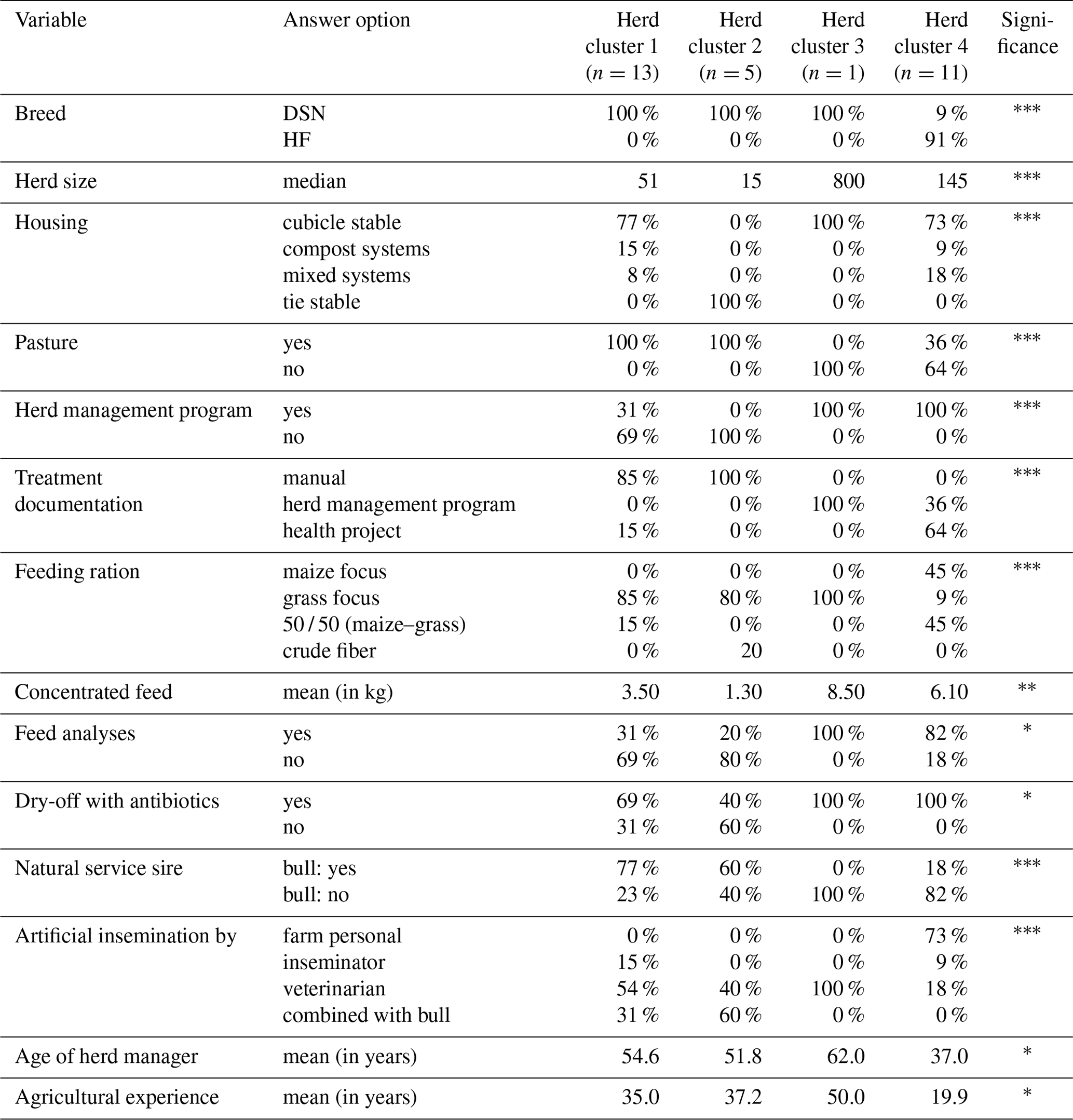
1 Fisher's exact test was used for quality variables and Kruskal–Wallis test for quantitative variables to test for significant differences among the herd clusters (* p<0.05, p<0.01, p<0.001).
It is interesting to note that both the HC1 and HC2 clusters included a mixture of conventional and organic herds, despite the substantial differences in legal regulations for both farming types. The organic farms from the present study base their feeding, breeding and management strategies on the guidelines for organic farming as defined by the European Union which are less strict than national German organic programs. Some particularities are defined in the basic principles for organic farming (IFOAM, 2020), especially addressing the breeding focus on longevity. Nevertheless, the allocation of organic as well as conventional herds to HC1 and HC2 suggests that there is an overlap of environmental conditions such as climatic impact between these two main classes (organic and conventional) affecting livestock production. Sorge et al. (2016) investigated herd management practices in organic and conventional dairy herds in Minnesota. They made similar conclusions, i.e., indicating that management decisions are diverse and herd specific, and do not strongly depend on the overall farming type organic or conventional. All of the HF herds as allocated to HC4 were conventional herds.
The majority of cows are kept in cubicle stables (HC1: 77 % of the herds, HC3: 100 % of the herds, HC4: 100 % of the herds) (Table 2). HC2 includes all herds with tie stables (16.7 % of all herds or 1.8 % of the cows), which usually have less than 20 cows. As identified for HC1, all cows in HC2 have access to pasture. In contrast, only one-third of the high-yielding herds (HC3 and HC4) reflect grazing systems. Accordingly, Müller-Lindenlauf et al. (2010) reported that herd productivity decreases with increasing length of the grazing period.
The cluster process (CoVAHC) separated the more traditional herds (herds in HC1 and HC2) from the more modern dairy herds (herds in HC3 and HC4). The level of digitization in animal housing, especially in dairy cattle farms, was defined as a major factor explaining herd and cow trait differences (Büscher, 2019). Herds allocated to HC2 did not use modern digital infrastructure (Table 2). Also, in HC1, the proportion of herds using a herd management software was comparatively low with 31 %. With regard to feeding strategies, herds from HC1 and HC2 use a very simple feed ration with only a few components, and they do not consider systematic feed analyses. In contrast, all herds in HC3 and HC4 base their management decisions on digital supporting systems. Also, the feeding rations are optimized considering scientific aspects and the needs of the cows. In total, 64 % of the herds from HC4 feed on a ration with a broad variety of ingredients.
The percentage of herds using natural service sires substantially differed among the HC (Table 2). The proportion was highest in HC1 with 77 %, followed by HC2 with 60 % but was quite low in HC4 (18 %). Herds from HC3 only considered artificial insemination. From a breeding perspective, Yin et al. (2014) identified utilization of natural service sires as a major characteristic when comparing organic with conventional farm types or DSN with HF herds.
With regard to social characteristics, mainly young farmers are responsible for the herd management in large-scale herds. Such a finding is in agreement with a comprehensive study across European dairy cattle herds (Blanco-Penedo et al., 2019). In HC4, the average age of herd managers was 37 years (Table 2). Nevertheless, the quite young farmers had substantial 20 years' experience in managing large-scale cow herds. The older farmers (average: 51.8 years with 37.2 years of agricultural experience) mainly managed the smaller herds (median: 15 cows) with tie stables (i.e., the herds from HC2).
3.3 Cow trait comparisons for the defined herd clusters
The comparison of LSM for test-day traits revealed significant differences (P<0.05; application of the Student's t test for pairwise differences) among the four HCs (Table 3). Hence, the different herd management strategies and farm characteristics as used for herd allocations simultaneously contributed to herd stratifications according to cow traits. A focus on milk production and high productivity was strongly associated with herd size. These herds were mostly assigned to HC3 (i.e., the “untypical DSN herd” with strong breeding focus on milk yield) and HC4 (i.e., the cluster including HF herds). Similar associations among herd variables and cow traits were reported by Müller-Lindenlauf et al. (2010), Ivemeyer et al. (2017) and Wallenbeck et al. (2018). HC2 represented herds with the lowest production level in Mkg (15.8 kg) and smallest herd sizes with a median of 15 cows. The mean production level of cows from HC1 was 21.2 kg milk, and the average herd size comprised 51 cows. The high-yielding HC3 and HC4 (HC3: 29.0 kg; HC4: 28.0 kg) represented the large-scale herds with 800 and 145 milking cows, respectively.
Table 3Least square means and corresponding standard errors of test day and fertility traits in the first three lactations for four herd clusters created with CoVAHC.
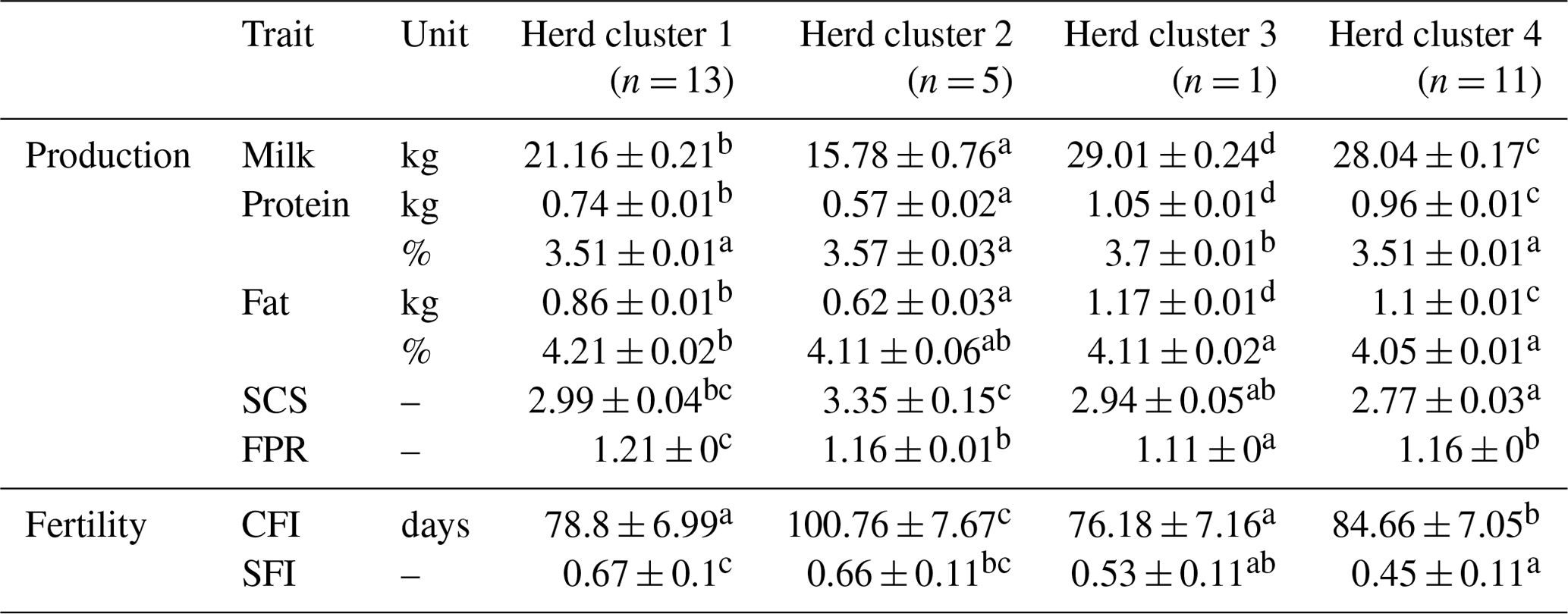
Least square means in the same row with different superscripts a, b, c or d are statistically significant different at p<0.05, the lowest least square means value is indicated by a up to the highest value d. SCS is the somatic cell score, FPR is the fat protein ratio, CFI is the time from calving to first insemination, and SFI is the success of a first insemination.
Cows from HC3 had the highest P% (3.7 %), but the remaining HCs did not differ significantly (P>0.05) for P% (Table 3). However, Pkg among HC differed significantly, which is due to the large differences in milk production. Similar observations were made for F% and Fkg.
HC2 comprised the herds with the highest SCS (average SCS: 3.35) (Table 3). In herds from HC2, all cows are housed in isolated tie stables with quite high air temperature and humidity. Inadequate hygiene and climate management contributed to impaired immune responses due to toxic gases (Barkema et al., 1999), resulting in increased SCS. Most of these herds (60 %) used an alternative dry-off management without antibiotic treatments. In contrast, the cows from the remaining HC are predominantly kept in loose housing and cold stalls, and the dry-off management is mostly based on antibiotic applications. The optimal climatic husbandry conditions plus preventive veterinary treatments might be an explanation for lower SCS in HC1 (2.99), HC3 (2.94) and HC4 (2.77) compared to HC2. Doherr et al. (2007) associated herd size with an increasing risk for clinical mastitis. In contrast, we identified lower SCS in HCs representing the large-scale herds. Doherr et al. (2007) and Ivemeyer et al. (2011) reported significant breed effects on SCS, indicating impaired udder health for HF cows. In our study, HC4 comprised all HF herds, and SCS in HC4 was lowest. Thus, the herd management and climatic conditions might have a stronger impact on the udder health status than herd size or breed (Barkema et al., 2015).
A FPR larger than 1.5 is an indicator for subclinical ketosis (Heuer et al., 1999). Surprisingly, the high productive DSN herd in HC3 considering large percentages of concentrates in the feeding ration is characterized by a significantly lower FPR (1.11) compared to the DSN herds from HC1 (1.21) and HC2 (1.16). The influence of the breed on FPR as described by Ivemeyer et al. (2019) was not confirmed in the present study, because the FPR in the “HF cluster” (HC4) was 1.16.
The LSM for SFI in HC1 (67 %) and HC2 (66 %) was significantly higher than in HC3 (53 %) and HC4 (45 %). The high proportion of natural matings in HC1 and HC2 (77 % and 60 %, respectively) explains such differences. Andersen-Ranberg et al. (2005) and Löf et al. (2012) reported a longer voluntary waiting period for a first insemination after calving in high-yielding herds. In our study, cows from HC1 and HC3 displayed the shortest CFI with 78.8 and 76.2 d, respectively, but both HC differed significantly with regard to milk yield (HC1: 15.8 kg vs. HC3: 29.0 kg).
3.4 Impact of herd clustering on genetic evaluations
Reliabilities of EBVs considering the whole population (cows and sires) and only for sires are given in Table 4. Statistical models including a herd-cluster-test-day or a herd-cluster-test-month effect increased the reliability in the entire population by 3.1 % and 3.5 %, respectively. Regarding sires, the increase was 5.1 % (herd-cluster test day) and 5.7 % (herd-cluster test month). Hence, the detailed consideration of environmental conditions and herd characteristics contributed to an increase of EBV reliabilities in the range from 3 % to 6 %, reflecting the postulations by Zwald et al. (2003) and Osorio-Avalos et al. (2015). The herd cluster instead of the herd effect for the CG modeling contributed to increased heritability estimates from 0.23 (herd-test-day effect and herd-test-month effect, respectively) to 0.36 (herd-cluster-test-day effect) or to 0.38 (herd-cluster-test-month effect).
Table 4Heritabilities (h2) with standard errors (SE) and reliabilities of estimated breeding values (R2) with standard deviations (SD) for the test-day model with herd or herd-cluster effects and for the test-month model with herd or herd-cluster effect for the whole population and for sires with daughter records.
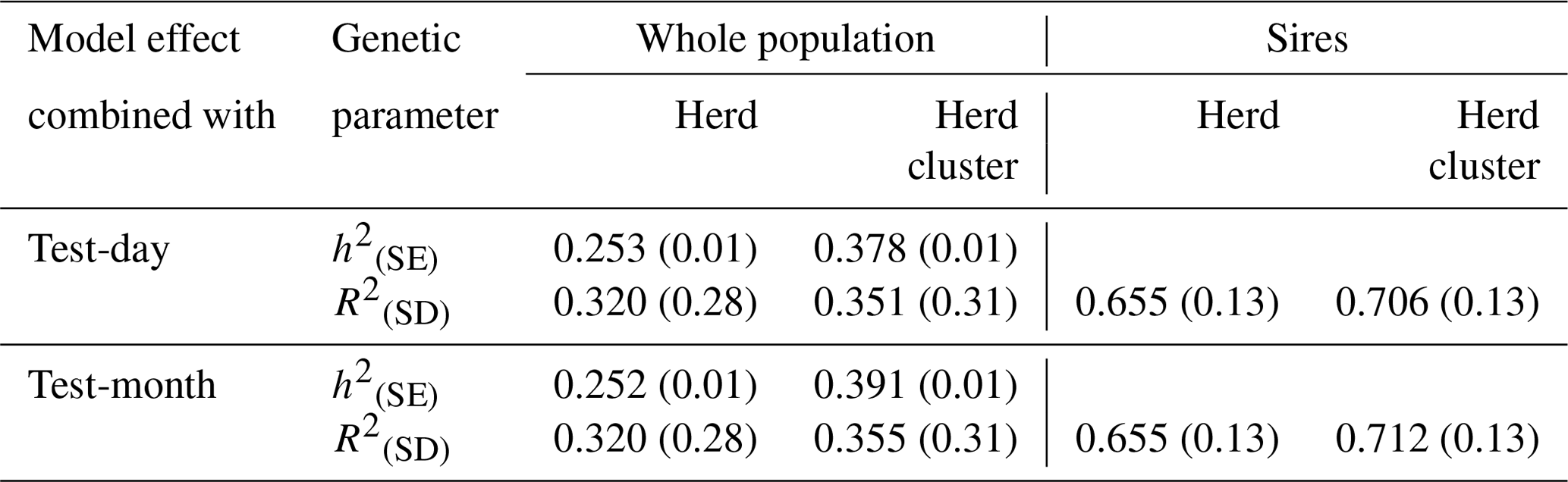
The creation of herd-test-day effects in genetic evaluations for local breeds with small population size generally implies a limited number of records or animals in CG. This, in turn, can lead to biased genetic calculations (Strabel and Szwaczkowski, 1999). As an alternative, HC or HC-test-month effects were suggested as CG effects in genetic–statistical modeling approaches (Vasconcelos et al., 2008). The general aim of CG creation is to depict environmental conditions influencing cow traits as detailed as possible (Kuehn et al., 2007; Osorio-Avalos et al., 2015). In this regard, a clear differentiation among HCs is imperative, as realized when applying the CoVAHC clustering approach. CoVAHC generated four different HCs with obvious herd similarities within HCs, implying 496 different CGs in herd-cluster-test-day models (model 3). A classical herd-test-day modeling approach would generate 603 CGs, with only a few records for some effect levels. A model based on CoVAHC HC avoided the problem of weakly occupied effect levels. The minimal number was three records per CG when considering the herd-cluster-test-day effect in model 3. Consequently, a genetic evaluation based on CoVAHC HC will contribute to an increase in the effective number of daughters (Tosh and Wilton, 1994). In this regard, Schmitz (1990) addressed the positive impact on breeding value accuracies, especially for breeds with a small population size.
A final severe issue in genetic evaluations is the computation time, which is generally time consuming in classical test-day models with a large number of herd-test-day effects. In this regard, models 3 and 4 on a HC basis were superior over classical herd-test-day or herd-test-month models, with on average 5 %–10 % reductions in computation time.
The superiority of the CoVAHC approach over the AHC, PAM and FZC methods for herd clustering in the local DSN population could be clearly demonstrated. In this regard, German DSN herds were clearly allocated to different HCs based on broad spectra of social–ecological and herd characteristics. Hence, we postulate also correct herd groupings in other German cattle populations, when considering similar descriptors for herd characterization and when applying CoVAHC clustering. Other clustering methods as developed for other fields of science including AHC, PAM and FZC are not appropriate (due to the obvious herd misclassifications) for animal breeding objectives. Utilization of herd clusters instead of single herds is suggested in genetic evaluations for breeds with a small population size kept in small-sized herds with a limited number of contemporaries. The suggestion is based on the observed increased EBV reliabilities and heritabilities. The clustering approach for herd allocation with corresponding ongoing genetic evaluations is an alternative also for large-sized populations, when creating different feeding or management groups in the same herd.
The housing and treatment of the animals were carried out in accordance with the German national regulations. The study was restricted to routine on-farm observations considering only data as used for national genetic evaluations plus data sets for herd characterization. All presented methods were non-invasive. Therefore, they did not cause the included animals pain, suffering or harm in compliance with the German Animal Welfare Act § 7.
The data that support the findings of this study are available from the authors upon reasonable request.
The supplement related to this article is available online at: https://doi.org/10.5194/aab-64-187-2021-supplement.
SK and KB designed the experiment and supervised the research. SK supported JH in writing and data validation. JH was responsible for farm characteristics and cow trait recording. JH and KB prepared the data and conducted the statistical analyses. All authors read and approved the manuscript.
The authors declare that they have no conflict of interest.
The authors thank the participating farms.
The project is supported by funds of the German Government's
Special Purpose Fund held at Landwirtschaftliche Rentenbank (grant no.
313-06.01-28-RZ-3.061).
This open-access publication was funded by Justus Liebig University Giessen.
This paper was edited by Antke-Elsabe Freifrau von Tiele-Winckler and reviewed by Dirk Hinrichs and Eva Strucken.
Ajmone-Marsan, P., Garcia, J. F., Lenstra, J. A., and The Globaldiv Consortium: On the origin of cattle: How aurochs became cattle and colonized the world, Evol. Anthropol., 19, 148–157, https://doi.org/10.1002/evan.20267, 2010.
Ali, A. A. K. and Shook, E. G.: An optimum transformation for somatic cell concentration in milk, J. Dairy Sci., 63, 487–490, https://doi.org/10.3168/jds.S0022-0302(80)82959-6, 1980.
Andersen-Ranberg, I. M., Klemetsdal, G., Heringstad, B., and Steine, T.: Heritabilities, Genetic correlations, and genetic change for female fertility and protein yield in Norwegian dairy cattle, J. Dairy Sci., 88, 348–355, https://doi.org/10.3168/jds.S0022-0302(05)72694-1, 2005.
Barkema, H. W., van der Ploeg, J. D., Schukken, Y. H., Lam, T. J. G. M., Benedictus, G., and Brand, A.: Management style and its association with bulk milk somatic cell count and incidence rate of clinical mastitis, J. Dairy Sci., 82, 1656–1663, https://doi.org/10.3168/jds.S0022-0302(99)75394-4, 1999.
Barkema, H. W., von Keyserlingk, M. A. G., Kastelic, J. P., Lam, T. J. G. M., Luby, C., Roy, J.-P., LeBlanc, S. J., Keefe, G. P., and Kelton, D. F.: Invited review: Changes in the dairy industry affecting dairy cattle health and welfare, J. Dairy Sci., 98, 7426–7445, https://doi.org/10.3168/jds.2015-9377, 2015.
Biedermann, G., Poppinga, O., and Weitemeyer, I.: Die genetische Struktur der Population des Schwarzbunten Niederungsrindes, Züchtungskunde, 77, 3–14, 2005.
Biscarini, F., Nicolazzi, E. L., Stella, A., Boettcher, P. J., and Gandini, G.: Challenges and opportunities in genetic improvement of local livestock breeds, Front. Genet., 6, 33, https://doi.org/10.3389/fgene.2015.00033, 2015.
Blanco-Penedo, I., Sjöström, K., Jones, P., Krieger, M., Duval, J., van Soest, F., Sundrum, A., and Emanuelson, U.: Structural characteristics of organic dairy farms in four European countries and their association with the implementation of animal health plans, Agr. Syst., 173, 244–253, https://doi.org/10.1016/j.agsy.2019.03.008, 2019.
Brida, J. G., Fasone, V., Scuderi, R., and Zapata-Aguirre, S.: ClustOfVar and the segmentation of cruise passengers from mixed data: Some managerial implications, Knowl.-based Syst., 70, 128–136, https://doi.org/10.1016/j.knosys.2014.06.016, 2014.
Brotzman, R. L., Cook, N. B., Nordlund, K., Bennett, T. B., Gomez Rivas, A., and Döpfer, D.: Cluster analysis of dairy herd improvement data to discover trends in performance characteristics in large upper Midwest dairy herds, J. Dairy Sci., 98, 3059–3070, https://doi.org/10.3168/jds.2014-8369, 2015.
Büscher, W.: Digitalisierung des Stalles – aktueller Stand und Perspektiven, Züchtungskunde, 91, 35–44, 2019.
Cervantes, I., Gutiérrez, J. P., and Meuwissen, T. H. E.: Response to selection while maximizing genetic variance in small populations, Genet. Sel. Evol., 48, 69, https://doi.org/10.1186/s12711-016-0248-3, 2016.
Chavent, M., Kuentz-Simonet, V., Liquet, B., and Saracco, J.: ClustOfVar: An R package for the clustering of variables, J. Stat. Softw., 50, https://doi.org/10.18637/jss.v050.i13, 2012.
Chavent, M., Kuentz-Simonet, V., Liquet, B., and Saracco, J.: ClustOfVar: Clustering of Variables, R package version 1.1., available at: https://CRAN.R-project.org/package=ClustOfVar (last access: 25 May 2021), 2017.
Doherr, M. G., Roesch, M., Schaeren, W., Schallibaum, M., and Blum, J. W.: Risk factors associated with subclinical mastitis in dairy cows on Swiss organic and conventional production system farms, Vet. Med.-Czech., 52, 487–495, https://doi.org/10.17221/2060-VETMED, 2007.
Ebinghaus, A.: Human-animal relationship in dairy farming: Evaluation of measures for on-farm application and investigation of influences on cows' behaviour towards humans, PhD thesis, University of Kassel, Kassel, Germany, 2018.
Emmerling, R.: Optimierung der Zuchtwertschätzung für Milchleistungsmerkmale unter besonderer Berücksichtigung der Umwelteinflüsse in einem Testtagsmodell, Dissertation, Munich, Germany, 2000.
Fernández, J., Meuwissen, T. H. E., Toro, M. A., and Mäki-Tanila, A.: Management of genetic diversity in small farm animal populations, Animal, 5, 1684–1698, https://doi.org/10.1017/S1751731111000930, 2011.
Gagaoua, M., Picard, B., Soulat, J., and Monteils, V.: Clustering of sensory eating qualities of beef: Consistencies and differences within carcass, muscle, animal characteristics and rearing factors, Livest. Sci., 214, 245–258, https://doi.org/10.1016/j.livsci.2018.06.011, 2018.
Gorgulu, O.: Classification of dairy cattle in terms of some milk yield characteristics by using Fuzzy Clustering, J. Anim. Vet. Adv., 9, 1947–1951, https://doi.org/10.3923/javaa.2010.1947.1951, 2010.
Gower, J. C.: A general coefficient of similarity and some of its properties, Biometrics, 27, 857, https://doi.org/10.2307/2528823, 1971.
Guiomar, N., Godinho, S., Pinto-Correia, T., Almeida, M., Bartolini, F., Bezák, P., Biró, M., Bjørkhaug, H., Bojnec, Š., Brunori, G., Corazzin, M., Czekaj, M., Davidova, S., Kania, J., Kristensen, S., Marraccini, E., Molnár, Z., Niedermayr, J., O'Rourke, E., Ortiz-Miranda, D., Redman, M., Sipiläinen, T., Sooväli-Sepping, H., Šūmane, S., Surová, D., Sutherland, L. A., Tcherkezova, E., Tisenkopfs, T., Tsiligiridis, T., Tudor, M. M., Wagner, K., and Wästfelt, A.: Typology and distribution of small farms in Europe: Towards a better picture, Land Use Policy, 75, 784–798, https://doi.org/10.1016/j.landusepol.2018.04.012, 2018.
Halli, K., Brügemann, K., Bohlouli, M., and König, S.: Time-lagged and acute impact of heat stress on production and fertility traits in the local dual-purpose cattle breed “Rotes Höhenvieh” under pasture-based conditions, Transl. Anim. Sci., 4, txaa148, https://doi.org/10.1093/tas/txaa148, 2020.
Heuer, C., Schukken, Y. H., and Dobbelaar, P.: Postpartum body condition score and results from the first test Day milk as predictors of disease, fertility, yield, and culling in commercial dairy herds, J. Dairy Sci., 82, 295–304, https://doi.org/10.3168/jds.S0022-0302(99)75236-7, 1999.
IFOAM: The IFOAM Principles of Organic Agriculture, available at: https://www.ifoam.bio/en/organic-landmarks/principles-organic-agriculture, last access: 14 April 2020.
Ivemeyer, S., Knierim, U., and Waiblinger, S.: Effect of human-animal relationship and management on udder health in Swiss dairy herds, J. Dairy Sci., 94, 5890–5902, https://doi.org/10.3168/jds.2010-4048, 2011.
Ivemeyer, S., Brinkmann, J., March, S., Simantke, C., Winckler, C., and Knierim, U.: Major organic dairy farm types in Germany and their farm, herd, and management characteristics, Organic Agriculture, 8, 231–247, https://doi.org/10.1007/s13165-017-0189-3, 2017.
Ivemeyer, S., Simantke, C., Knierim, U., Spengler Neff, A., and Bieber, A.: Gesundheits- und Produktionsmerkmale der lokalen Rasse Anglerrind alter Zuchtrichtung und der weit verbreiteten Rasse Holstein auf extensiv wirtschaftenden Biomilchviehbetrieben, [Health and production characteristics of the local breed Original Angler Cattle (“Anglerrind alter Zuchtrichtung”) and the commercial breed Holstein on extensive organic dairy farms], in: Innovatives Denken für eine nachhaltige Land- und Ernährungswirtschaft, Beiträge zur 15. Wissenschaftstagung Ökologischer Landbau, edited by: Mühlrath, D., Albrecht, J., Finckh, M. R., Hamm, U., Heß, J., Knierim, U., and Möller, D., Kassel, Germany, 5–8 March 2019, 2019.
Jaeger, M., Scheper, C., König, S., and Brügemann, K.: Studien zur Inzucht und Verwandtschaft beim “Deutschen Schwarzbunten Niederungsrind” (DSN) auf Basis eigens berechneter Rasseanteile, Züchtungskunde, 90, 262–279, 2018.
Jaeger, M., Brügemann, K., Naderi, S., Brandt, H., and König, S.: Variance heterogeneity and genotype by environment interactions in native Black and White dual-purpose cattle for different herd allocation schemes, Animal, 13, 2146–2155, https://doi.org/10.1017/S1751731119000144, 2019.
Kaufman, L. and Rousseeuw, P. J.: Finding groups in data, John Wiley & Sons, Inc, Hoboken, New Jersey, USA, 1990.
Kennedy, B. W. and Trus, D.: Considerations on genetic connectedness between management units under an animal model, J. Anim. Sci., 71, 2341–2352, https://doi.org/10.2527/1993.7192341x, 1993.
Köbrich, C., Rehman, T., and Khan, M.: Typification of farming systems for constructing representative farm models: two illustrations of the application of multi-variate analyses in Chile and Pakistan, Agr. Syst., 76, 141–157, https://doi.org/10.1016/S0308-521X(02)00013-6, 2003.
König, S., Dietl, G., Raeder, I., and Swalve, H. H.: Genetic relationships between dairy performance under large-scale farm and family farm conditions, J. Dairy Sci., 88, 4087–4096, https://doi.org/10.3168/jds.S0022-0302(05)73093-9, 2005.
Kuehn, L. A., Lewis, R. M., and Notter, D. R.: Managing the risk of comparing estimated breeding values across flocks or herds through connectedness: a review and application, Genet. Sel. Evol., 39, 225–247, https://doi.org/10.1051/gse:2007001, 2007.
Kuentz-Simonet, V., Lyser, S., Candau, J., and Deuffic, P.: ClustOfVar-based approach for unsupervised learning: Reading of synthetic variables with sociological data, Electronic Journal of Applied Statistical Analysis, 8, 170–197, https://doi.org/10.1285/I20705948V8N2P170, 2015.
Kuentz-Simonet, V., Labenne, A., and Rambonilaza, T.: Using ClustOfVar to construct quality of life indicators for vulnerability assessment municipality trajectories in Southwest France from 1999 to 2009, Soc. Indic. Res., 131, 973–997, https://doi.org/10.1007/s11205-016-1288-3, 2017.
Lenth, R.: emmeans: Estimated marginal means, aka Least-Squares Means, R package, version 1.4.8., available at: https://CRAN.R-project.org/package=emmeans (last access: 25 May 2021), 2020.
Lletí, R., Ortiz, M. C., Sarabia, L. A., and Sánchez, M. S.: Selecting variables for k-means cluster analysis by using a genetic algorithm that optimises the silhouettes, Anal. Chim. Acta, 515, 87–100, https://doi.org/10.1016/j.aca.2003.12.020, 2004.
Löf, E., Gustafsson, H., and Emanuelson, U.: Evaluation of two dairy herd reproductive performance indicators that are adjusted for voluntary waiting period, Acta Vet. Scand., 54, 5, https://doi.org/10.1186/1751-0147-54-5, 2012.
Madsen, P. and Jensen, J.: DMU: A Package for analysing multivariate mixed models, available at: http://dmu.agrsci.dk/DMU/Doc/Current/dmuv6_guide.5.2.pdf (last access: 10 April 2016), 2013.
Maechler, M., Rousseeuw, P., Struyf, A., Hubert, M., and Hornik, K.: cluster: Cluster analysis basics and extensions: R package,version 2.0.7-1, available at: https://cran.r-project.org/web/packages/cluster/index.html (last access: 25 May 2021), 2018.
Maione, C., Nelson, D. R., and Barbosa, R. M.: Research on social data by means of cluster analysis, Applied Computing and Informatics, 15, 153–162, https://doi.org/10.1016/j.aci.2018.02.003, 2019.
Martin-Collado, D., Soini, K., Mäki-Tanila, A., Toro, M. A., and Diaz, C.: Defining farmer typology to analyze the current state and development prospects of livestock breeds: The Avinela-Negra Iberica beef cattle breed as a case study, Livest. Sci., 169, 137–145, 2014.
Mastrangelo, S., Tolone, M., Di Gerlando, R., Fontanesi, L., Sardina, M. T., and Portolano, B.: Genomic inbreeding estimation in small populations: evaluation of runs of homozygosity in three local dairy cattle breeds, Animal, 10, 746–754, https://doi.org/10.1017/S1751731115002943, 2016.
Müller-Lindenlauf, M., Deittert, C., and Köpke, U.: Assessment of environmental effects, animal welfare and milk quality among organic dairy farms, Livest. Sci., 128, 140–148, https://doi.org/10.1016/j.livsci.2009.11.013, 2010.
Murtagh, F. and Legendre, P.: Ward's hierarchical agglomerative clustering method: Which algorithms implement Ward's criterion?, J. Classif., 31, 274–295, https://doi.org/10.1007/s00357-014-9161-z, 2014.
Osorio-Avalos, J., Menéndez-Buxadera, A., Serradilla, J. M., and Molina, A.: Use of descriptors to define clusters of herds under similar environmental conditions to improve the level of connection among contemporary groups of mutton type merino sheep under an extensive production system, Livest. Sci., 176, 54–60, https://doi.org/10.1016/j.livsci.2015.03.029, 2015.
Pereira, R. J., Schenkel, F. S., Ventura, R. V., Ayres, D. R., El Faro, L., Machado, C. H. C., and Albuquerque, L. G.: Contemporary group alternatives for genetic evaluation of milk yield in small populations of dairy cattle, Anim. Prod. Sci., 59, 1022–1030, https://doi.org/10.1071/AN17551, 2018.
Pimenta, V., Barroso, I., Boitani, L., and Beja, P.: Wolf predation on cattle in Portugal: Assessing the effects of husbandry systems, Biol. Conserv., 207, 17–26, https://doi.org/10.1016/j.biocon.2017.01.008, 2017.
R Core Team: A language and environment for statistical computing, R Foundation for Statistical Computing, Vienna, Austria, available at: http://www.R-project.org, last access: 11 August 2020.
Riveiro, J. A., Mantecón, A. R., Álvarez, C. J., and Lavín, P.: A typological characterization of dairy Assaf breed sheep farms at NW of Spain based on structural factor, Agr. Syst., 120, 27–37, https://doi.org/10.1016/j.agsy.2013.05.004, 2013.
Rousseeuw, P. J.: Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20, 53–65, https://doi.org/10.1016/0377-0427(87)90125-7, 1987.
Salasya, B. and Stoorvogel, J.: Fuzzy classification for farm household characterization, Outlook Agr., 39, 57–63, https://doi.org/10.5367/000000010791169961, 2010.
Savoia, S., Brugiapaglia, A., Pauciullo, A., Di Stasio, L., Schiavon, S., Bittante, G., and Albera, A.: Characterisation of beef production systems and their effects on carcass and meat quality traits of Piemontese young bulls, Meat Sci., 153, 75–85, https://doi.org/10.1016/j.meatsci.2019.03.010, 2019.
Schmitz, F., Everett, R. W., and Quaas, R. L.: Herd-year-season clustering, J. Dairy Sci., 74, 629–636, https://doi.org/10.3168/jds.S0022-0302(91)78210-6, 1990.
Sorge, U. S., Moon, R., Wolff, L. J., Michels, L., Schroth, S., Kelton, D. F., and Heins, B.: Management practices on organic and conventional dairy herds in Minnesota, J. Dairy Sci., 99, 3183–3192, https://doi.org/10.3168/jds.2015-10193, 2016.
Strabel, T. and Szwaczkowski, T.: The use of test day models with small size of contemporary groups, J. Anim. Breed. Genet., 116, 379–386, https://doi.org/10.3168/jds.S0022-0302(05)73055-1, 1999.
Strabel, T., Szyda, J., Ptak, E., and Jamrozik, J.: Comparison of random regression test-day models for polish black and white cattle, J. Dairy Sci., 88, 3688–3699, https://doi.org/10.3168/jds.S0022-0302(05)73055-1, 2005.
Struyf, A., Hubert, M., and Rousseeuw, P.: Clustering in an object-oriented environment, J. Stat. Softw., 1, https://doi.org/10.18637/jss.v001.i04, 1996.
Toro, M. A., Meuwissen, T. H. E., Fernández, J., Shaat, I., and Mäki-Tanila, A.: Assessing the genetic diversity in small farm animal populations, Animal, 5, 1669–1683, https://doi.org/10.1017/S1751731111000498, 2011.
Toro-Mujica, P., García, A., Gómez-Castro, A., Perea, J., Rodríguez-Estévez, V., Angón, E., and Barba, C.: Organic dairy sheep farms in south-central Spain: Typologies according to livestock management and economic variables, Small Ruminant Res., 104, 28–36, https://doi.org/10.1016/j.smallrumres.2011.11.005, 2012.
Tosh, J. J. and Wilton, J. W.: Effects of data structure on variance of prediction error and accuracy of genetic evaluation, J. Anim. Sci., 72, 2568–2577, https://doi.org/10.2527/1994.72102568x, 1994.
Tremblay, M., Hess, J. P., Christenson, B. M., McIntyre, K. K., Smink, B., van der Kamp, A. J., de Jong, L. G., and Döpfer, D.: Customized recommendations for production management clusters of North American automatic milking systems, J. Dairy Sci., 99, 5671–5680, https://doi.org/10.3168/jds.2015-10153, 2016.
Vasconcelos, J., Santos, F., Bagnato, A., and Carvalheira, J.: Effects of clustering herds with small-sized contemporary groups in dairy cattle genetic evaluations, J. Dairy Sci., 91, 377–384, https://doi.org/10.3168/jds.2007-0202, 2008.
Wallenbeck, A., Rousing, T., Sørensen, J. T., Bieber, A., Spengler Neff, A., Fuerst-Waltl, B., Winckler, C., Peiffer, C., Steininger, F., Simantke, C., March, S., Brinkmann, J., Walczak, J., Wójcik, P., Ribikauskas, V., Wilhelmsson, S., Skjerve, T., and Ivemeyer, S.: Characteristics of organic dairy major farm types in seven European countries, Organic Agriculture, 98, 7426, https://doi.org/10.1007/s13165-018-0227-9, 2018.
Ward, J. H.: Hierarchical grouping to optimize an objective function, J. Am. Stat. Assoc., 58, 236, https://doi.org/10.2307/2282967, 1963.
Weigel, K. and Rekaya, R.: Clustering herds across country borders for international genetic evaluation, J. Dairy Sci., 4, 815–821, https://doi.org/10.3168/jds.S0022-0302(00)74944-7, 1999.
Yin, T., Wensch-Dorendorf, M., Simianer, H., Swalve, H. H., and König, S.: Assessing the impact of natural service bulls and genotype by environment interactions on genetic gain and inbreeding in organic dairy cattle genomic breeding programs, Animal, 8, 877–886, 2014.
Zwald, N. R., Weigel, K. A., Fikse, W. F., and Rekaya, R.: Application of a multiple-trait herd cluster model for genetic evaluation of dairy sires from seventeen countries, J. Dairy Sci., 86, 376–382, https://doi.org/10.3168/jds.S0022-0302(03)73616-9, 2003.